Computers and the algorithms they run are precise, perfect, meticulously programmed, and austere. That’s the idea, anyway. But there’s a burgeoning, alternative model of programming and computation that sidesteps the limitations of the classic model, embracing uncertainty, variability, self-correction, and overall messiness. It’s called machine learning, and it’s impacted fields as diverse as facial recognition, movie recommendations, real-time trading, and cancer research—as well as all manner of zany experiments, like Google’s image-warping Deep Dream. Yet even within computer science, machine learning is notably opaque. In his new book The Master Algorithm, Pedro Domingos covers the growing prominence of machine learning in close but accessible detail. Domingos’ book is a nontechnical introduction to the subject, but even if it still seems daunting, it’s important to understand how machine learning works, the many forms it can take, and how it’s taking on problems that give traditional computing a great deal of trouble. Machine learning won’t bring us a utopian singularity or a dystopian Skynet, but it will inform an increasing amount of technology in the decades to come.
While machine learning originated as a subfield of artificial intelligence—the area of computer science dedicated to creating humanlike intelligence in computers—it’s expanded beyond the boundaries of A.I. into data science and expert systems. But machine learning is fundamentally different from much of what we think of as programming. When we think of a computer program (or the algorithm a program implements), we generally think of a human engineer giving a set of instructions to a computer, telling it how to handle certain inputs that will generate certain outputs. The state maintained by the program changes over time—a Web browser keeps track of which pages it’s displaying and responds to user input by (ideally) reacting in a determinate and predictable fashion—but the logic of the program is essentially described by the code written by the human. Machine learning, in many of its forms, is about building programs that themselves build programs. But these machine-generated programs—neural networks, Bayesian belief networks, evolutionary algorithms—are nothing like human-generated algorithms. Instead of being programmed, they are “trained” by their designers through an iterative process of providing positive and negative feedback on the results they give. They are difficult (sometimes impossible) to understand, tricky to debug, and harder to control. Yet it is precisely for these reasons that they offer the potential for far more “intelligent” behavior than traditional approaches to algorithms and A.I.
Domingos’ book is, to the best of my knowledge, the first general history of the machine-learning field. He covers the alternate paradigms that gave rise to machine learning in the middle of the 20th century, the “connectionism” field’s fall from grace in the 1960s, and its eventual resurrection and surpassing of traditional A.I. paradigms in the 1980s to the present. Domingos divides the field into five contemporary machine-learning paradigms—evolutionary algorithms, connectionism and neural networks, symbolism, Bayes networks, and analogical reasoning—which he imagines being unified in one future “master algorithm” capable of learning nearly anything.
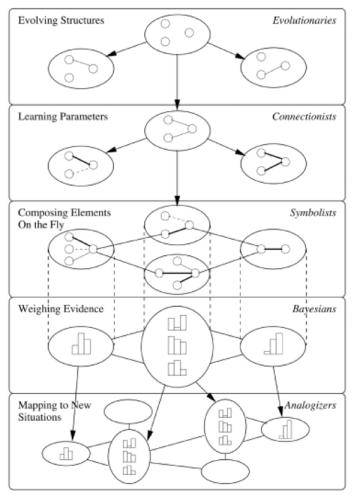
from The Master Algorithm
None of these five paradigms admits to easy explanation. Take, for example, the neural networks that gave us Google’s Deep Dream—that thing you’ve seen that turns everyday photos into horrorscapes of eyeballs and puppy heads—as well as a surprisingly successful image-recognition algorithm that learned to recognize cat faces without any supervision. They consist of math-intensive calculations of thousands of interacting “neurons,” each with conditioned weights that determine when they “fire” outputs to other connected neurons. As these networks receive data on whether they are generating good results or not, they update their weights with the goal of improving the results. The feedback may not immediately fix a wrong answer. With enough wrong answers, though, the weights will change to skew away from that range of wrong answers. It’s this sort of indirect, probabilistic control that characterizes much of machine learning.
The question, then, is why one would want to generate opaque and unpredictable networks rather than writing strict, effective programs oneself. The answer, as Domingos told me, is that “complete control over the details of the algorithm doesn’t scale.” There are three related aspects to machine learning that mitigate this problem:
(1) It uses probabilities rather than the true/false binary.
(2) Humans accept a loss of control and precision over the details of the algorithm.
(3) The algorithm is refined and modified through a feedback process.
These three factors make for a significant change from the traditional programming paradigm (the one which I myself inhabited as a software engineer). Machine learning creates systems that are less under our direct control but that—ideally—can respond to their own mistakes and update their internal states to improve gradually over time. Again, this is a contrast to traditional programming, where bugs are things to be ferreted out before release. Machine-learning algorithms are very rarely perfect and have succeeded best in cases where there’s a high degree of fault tolerance, such as search results or movie recommendations. Even if 20 percent of the results are noise, the result is still more “intelligent” than one might expect. A movie recommendation engine, even if it frequently messes up, may do as good a job recommending movies to you as your friends.
Machine learning has its roots as far back as the 1940s and 1950s, to cybernetic researchers like Warren McCulloch and Walter Pitts. They conceived of a computational model of a neuron that would vaguely resemble the biological neuron but in a vastly stripped-down and explicitly mathematical form. Yet their efforts were pioneering in the field of nonsymbolic A.I., which is to say, A.I. that focused less around the problems of representing knowledge logically and more around the issues of responding to the world—closer to robotics (like W. Grey Walter’s robot tortoises) than to HAL 9000.
In the 1950s and 1960s, neurobiologist Frank Rosenblatt took these ideas and applied them to computer vision, calling these primitive neural networks perceptrons, but the entire field took a hit when Marvin Minsky and Seymour Papert criticized the potential of perceptrons in a 1969 book. What prevailed in the 1970s was the “classical” A.I. model, sometimes termed symbolic A.I., knowledge representation, or GOFAI (Good Old-Fashioned A.I.), centered around the explicit, logical representation of facts about the world. “Horses have four legs” would be represented as something like
∀x (IS_HORSE(x) → NUM_LEGS(x) = 4)
which translates colloquially to, “For every entity, if that entity is a horse, then that entity has four legs.” There are just two problems. First, how is a computer supposed to “learn” this fact? Second, what about that small number of horses that, through surgery, accident, or mutation, don’t have four legs? Silly questions, perhaps, but, as I described when discussing Wittgenstein’s philosophy of language, ones that are important if computers must truly understand the world. When A.I. was more of a theoretical matter due to lack of computational processing ability, these sorts of concerns were easier to elide. But as technology caught up and researchers attempted to implement GOFAI, the limitations of the so-called knowledge representation model became clear. It had marked successes in limited contexts, such as strategic planning and expert systems, where the boundaries of a problem were clearly regimented and terms were explicitly defined. But in the amorphous and ambiguous larger world, it ran into trouble with those three-legged horses and with attempts at semantic understanding in general, which is why search engines still can’t answer questions but can only search for keywords. Attempts to build a large, generalized base of knowledge for A.I. to think with have been unsuccessful. This is what Domingos terms the “knowledge acquisition bottleneck: the labor-intensive acquisition of knowledge.”
This, then, is the promise of machine learning: By turning over the hard labor of this endless fine-tuning to an automatic process of feedback-driven tweaking to a mutating algorithm, we can get results that would be impossible to code by hand. I don’t think this will put today’s programmers out of jobs any time soon: There will still be a need for underlying classically programmed systems to support machine learning, if nothing else. Nonetheless, change is coming. Domingos told me that one main motivation for writing the book was to generate more interest from people outside the field, in order to shake up and advance it. “There are some important ideas that are still missing. Part of my goal was to let people have their own thoughts,” he said. Near the end of the book, Domingos pictures a world in which all of our interactions with technology generate feedback that causes machine-learning algorithms to fine-tune themselves, asymptotically growing closer to a perfect understanding of how the world and the people in it work: This is the “master algorithm,” one that is truly able to reason about people and the world. It is, as Domingos says, a very distant goal, but it’s one that is distinctly more plausible than the fever dreams of singularity enthusiasts or Skynet paranoiacs (both of whom Domingos pours a bit of cold water on). Machine learning is still a very long way from fulfilling the vision of A.I., but currently it is the most promising avenue for moving computers out of the perfect machine world and into the colossally messy realm of the natural and the human.
This article is part of Future Tense, a collaboration among Arizona State University, New America, and Slate. Future Tense explores the ways emerging technologies affect society, policy, and culture. To read more, visit the Future Tense blog and the Future Tense home page. You can also follow us on Twitter.