The classic Atari 2600 version of Ms. Pac-Man is brutally unforgiving, partly because it’s so unpredictable. In one recent emulator-assisted session, I managed a mere 26,000 points before being swallowed up by the game’s erratic antagonists. My score pales before those of the game’s true masters, but even they must cede their titles to the game’s new champion, an artificially intelligent system developed by Maluuba, a Microsoft-owned startup. Maluuba’s program managed to accumulate an astonishing 999,990 points—more than any player, human or machine, has managed before.
Maluuba achieved that formidable feat through a technique known as reinforcement learning. As Pedro Domingos explains in his book The Master Algorithm, reinforcement learning is a field “dedicated to algorithms that explore on their own, flail, hit on rewards, and figure out how to get them again in the future, much like babies crawling around and putting things in their mouths.” In the past, researchers with Google’s DeepMind have employed this approach to make computers teach themselves to play a variety of Atari games. Indeed, it’s often applied to gaming problems, though Domingos writes, “[R]esearchers have [also] used reinforcement learning to balance poles, control stick-figure gymnasts, park cars backward,” and a host of other tasks.
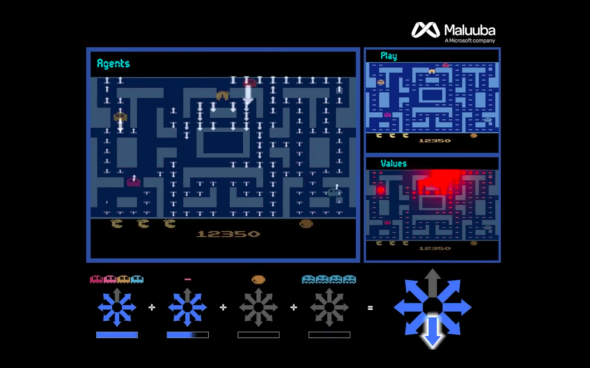
As Wired notes, however, Ms. Pac-Man has long been difficult for machines to master, partly because of the same randomized elements that make it hard for human players like me. To help overcome that challenge, the Maluuba team developed a method that it calls hybrid reward architecture. As team members explain in a paper on their work, that entailed decomposing the larger problem presented by the full gameplay board into a multitude of smaller problems. They assigned those sub-problems to 163 distinct reinforcement learning agents, each of them with different targets derived from their objects of interest, with some of them focusing on pellets, others on ghosts, and so on. As the program tries to decide what it should do next, those agents feed suggestions to a managerial agent. Taking all that information in, it weighs the possibilities and makes a decision that should maximize its score while keeping its avatar away from ghosts.
In the Register, Katyanna Quach and Andrew Silver throw a bit of cold water on the project. Calling Maluuba’s effort “a bit of clever trickery,” they point out that “reward weights are hardcoded into the software.” That is, their system already had the information it needed to master the game: Unlike DeepMind’s game-playing experiments, Maluuba’s system already knew that it was supposed to avoid ghosts, chase down fruits, and so on. Quach and Silver propose that this is reason enough to dismiss the project: “To be blunt, that means the algorithm isn’t very valuable to anyone, unless you want to watch a computer solve Ms. Pac-Man.”
But the Maluuba researchers insist that their method could have practical applications. “We argue that many real-world tasks allow for reward decomposition,” they write in their paper. Separating a task into discrete targets with defined weights, they argue, might be useful, since it decreases the “problem size,” making even the most complex issues more manageable. In a Microsoft blog post, one of the researchers suggests such an approach might, for example, “help a company’s sales organization make precise predictions about which potential customers to target at a particular time or on a particular day.”
That’s a disquieting prospect, in part because it assumes that humans can be broken down numerically like the bits and pieces in an old-school video game. We’ve known for years, of course, that computers can learn to play games better than humans will ever manage. But Maluuba seems to be hinting at something else: In the future, they propose, computers may be playing us.