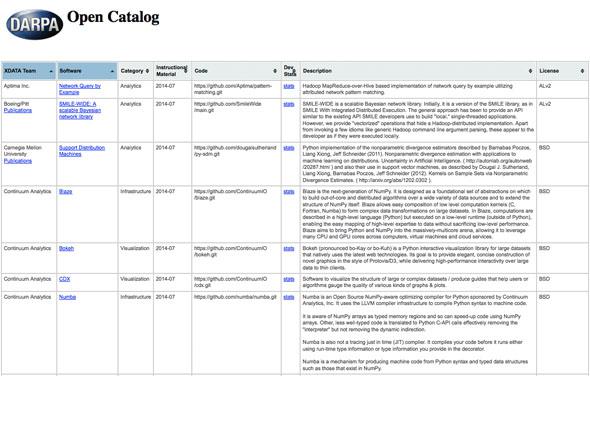
There’s a lot of great research happening all the time, but there’s also a lot of old data that sits around on external hard drives and lab computers and slowly disappears from memory. The Defense Advanced Research Projects Agency (DARPA) puts so much funding into private and academic research that the agency has decided enough is enough. They’ve created the DARPA Open Catalog as a repository for code and data that comes out of DARPA-funded work. The catalog is launching with 60 projects.
Chris White, who oversaw the creation of the Open Catalog, said in a statement:
Making our open source catalog available increases the number of experts who can help quickly develop relevant software for the government. Our hope is that the computer science community will test and evaluate elements of our software and afterward adopt them as either standalone offerings or as components of their products.
Many of the projects stored in the catalog so far have an emphasis on working with and manipulating large data sets, an important underpinning for things like cloud operations and research with supercomputers. But given the range of projects DARPA funds or works on directly, the catalog’s diversity should continue to grow.
DARPA’s statement says that the agency will continue to develop and expand the catalog based on the level of interest and support from the research community, and it already plans to update the catalog with data from the Broad Operational Language Translation program and the Visual Media Reasoning initiative.