
In recent years, Facebook’s news feed has been widely, and often justly, criticized for misinforming the public and distorting incentives in the journalism industry. Clickbait, fake news, political polarization and extremism: Facebook’s news feed has helped to fuel all of these trends, to one degree or another. And when we blame Facebook’s news feed for these sorts of things, we’re often blaming the news feed algorithm—the crucial piles of code that determine what content people see when they open the app, and in what order.
Only recently have critics begun to turn their attention to the other side of Facebook’s business, the one that the average Facebook user rarely sees: its advertising platform. What they’re finding there is disturbing in its own right: options to target people based on race or hate-group affiliations, “dark posts” that can be seen only by certain demographics, and a laissez-faire approach to sales that has evidently allowed Russian meddlers to purchase divisive U.S. political ads.
In these relatively early days of scrutiny of Facebook’s advertising tools, critics and the media have shown a tendency to assign blame to a familiar boogeyman: algorithms. But doing so risks obscuring the problems’ true source, which lies not within the bowels of intricate, opaque software programs, but in the basic structure of the company’s advertising business—and the decision-making of the humans who run it.
When ProPublica found last week that Facebook had been allowing advertisers to target users based on keywords such as “Jew-hater,” the publication asserted that such categories had been “created by an algorithm rather than by people.” From ProPublica’s story:
In all likelihood, the ad categories that we spotted were automatically generated because people had listed those anti-Semitic themes on their Facebook profiles as an interest, an employer or a “field of study.” Facebook’s algorithm automatically transforms people’s declared interests into advertising categories.
My own reporting at Slate echoed this vague explanation, as did follow-up stories across the web. Wired called the story “a sure sign that Facebook’s algorithms have run amok.” Recode ran a post by Kurt Wagner headlined, “Facebook’s Reliance on Software Algorithms Keeps Getting the Company Into Trouble.”
The use of the term algorithm might be defensible here in the strictest technical sense. It is true that Facebook’s ad tool relies on software, and all software contain algorithms of one sort of another. But a closer look at what was really going on with Facebook’s ad-targeting tool suggests that by framing this as an algorithm problem, we’re missing the point.
The word algorithm has different meanings to different people. In the math world, it simply means a set procedure by which a given class of problems can be solved. But in the context of Facebook, Google, and other big tech companies, it has popularly come to refer to the complex processes by which software programs turn reams of data into some kind of abstract output: a suggestion, a recommendation, or a decision. It often suggests a sort of agency on the software’s part, and an attempt by the software’s engineers to imbue it with some form of intelligence. So when one talks about problems with Facebook’s algorithm, there’s an implication that, on some level, the software is doing things that the humans who built it didn’t intend for it to do. (This interpretation does not absolve the humans; it just informs the discussion of what went wrong and how to fix it.)
By that definition, Facebook’s fake news problem—the one in which hoax articles such as “Pope Francis Shocks World, Endorses Donald Trump for President” went viral on the social network in the months before the 2016 election—is at least partly an algorithm problem: The company’s news feed software was designed to show people news they’re likely to be interested in, based on their online activity and that of their friends. But the very features of the algorithm that were supposed to make it a good source for news turned out to make it a potent tool for spreading misinformation that pandered to people’s political biases. Another classic example of an algorithm gone awry was when Google’s machine-learning-powered Photos app mistakenly labeled black people as gorillas, because it had been trained on a data set comprising mostly light-skinned people. In both of these cases, the problematic output was software-generated, though of course it stemmed from poor decisions made by the humans who coded the process.
But, contra ProPublica’s initial reporting (and mine), that wasn’t really the case with the offensive targeting terms allowed by Facebook’s advertising tool.
In the context of ads on Facebook, algorithm usually refers to the software that decides precisely which Facebook users within a target group to show a given ad, and exactly when to show it to them. Facebook also uses an algorithm to generate what it calls “interest” categories and to infer each user’s interests based on his or her online activity.
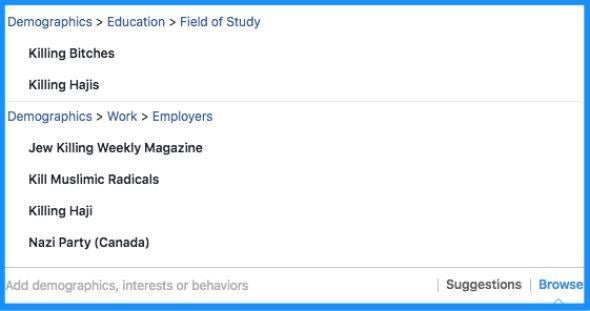
Screenshot
But “Jew-hater,” “killing hajis,” and the other hateful terms used in ads as part of investigations by ProPublica, Slate, and others were not “interest categories,” and they weren’t algorithmically generated, according to a Facebook spokesman. Rather, they were terms that one or more Facebook users had manually typed in to various fields in their profiles, such as “employer” or “field of study.” Far from relying on a complex algorithm, Facebook’s ad tool was hard-coded to allow advertisers to manually enter their own keywords in these fields and target ads based on any exact match with any user’s profile. A rudimentary auto-complete function aided in finding such matches. So if just one of Facebook’s 2 billion users entered “Jew-hater” as her “field of study”—whether out of malice or a misplaced attempt at humor—an advertiser who typed that same term in the same field could then include that user among the target audience. (Following ProPublica’s and Slate’s reports, Facebook disabled these targeting options.) To the extent there’s a problem, then, it’s not a case of machine intelligence run amok but rather a lack of any intelligence in the process, machine or otherwise. In short, Facebook’s ad tool is dumb.
Imagine your basic office vending machine. That’s Facebook’s ad tool. Now imagine that some troublemaker placed a grenade in slot E5, where the Snickers bars were supposed to go. (That’s the user who types “Jew-hater” in “field of study.”) If you see the grenade and press E5, and the vending machine gives you the grenade, that’s not an algorithm problem. It’s a people problem, in which a dumb technology allows people to make destructive choices that it was never designed to prevent.
Revisiting Facebook’s other big ad snafus yields a similar diagnosis.
One of the first came last year, when ProPublica showed that the company’s system was allowing people to discriminate between races in housing ads, which is illegal. (Facebook subsequently changed its system in an attempt to prevent such discrimination.) Facebook’s “ethnic affinity” categories were partly algorithmic: The categories themselves were human-generated, but users were placed in them based on the software’s analysis of their interests and activity. But the problem had very little to do with that sorting process. Rather, the problem was that Facebook’s dumb, self-serve ad tool had been hard-coded—by humans—to allow advertisers to use such categories for targeting in all ads, including types of ads where race-based discrimination is illegal. Again: a people problem.
And then there was the scandal that hit earlier this month, when Facebook disclosed to congressional investigators that it had found evidence of a Kremlin-linked organization buying a series of advertisements targeting U.S. voters with political propaganda. Once more, the problem was not the algorithmic process by which Facebook placed those ads in users’ news feeds. Rather, it was the fact that Facebook allowed such ads to be placed at all. And how did that happen? As the Verge reported on Monday, the ads had slipped past a team of human moderators who were paid to quickly evaluate different components of each advertisement for abuse, illegal activity, or violations of Facebook policy.
Some might object that this all boils down to semantic quibbling. Since even the simplest automation involves algorithms of some sort, it’s not technically inaccurate to say that algorithms were involved in each of these ad controversies. But how we frame the problem does matter, because it carries implications for how we might try to solve it.
Framing Facebook’s ad problems as algorithm problems suggests that they reside somewhere in the labyrinthine depths of Facebook’s proprietary code. Algorithm problems sound complicated, mysterious. They sound like problems that could be solved one of two ways: either through some sort of technical wizardry or by pulling back from the project of automation altogether, on the grounds that some tasks are just too nuanced to be trusted to machines.
In fact, the problems with Facebook’s ad tool are not mysterious or complicated, and they aren’t buried in layers of machine-learning classifiers or neural nets. Rather, they’re the predictable outcome of rudimentary automation coupled with bad human behavior and a lack of careful oversight. Facebook’s ad-targeting tool is hardly more algorithmic than a mechanical vending machine, and no more prone to making value judgments as to the merchandise it has for sale (in this case, human attention).
The reason is simple: It’s because Facebook’s approach to advertising has been, with few exceptions, to let just about anyone advertise to whomever they want, provided the content of the ad itself passes minimal standards of decency. In short, it’s treating packets of demographically targeted users like so many packets of differently flavored potato chips.
It’s a fine approach, if you view human attention as a commodity and your goal is simply to sell as much of it as possible to whoever’s buying. And by automating the process, Facebook has sold targeted ads on a scale that would be unthinkable if human oversight were required. It’s this automation that has made Facebook and its founders so fabulously wealthy. (The world’s only advertising company in the same league is Google, whose own targeting tools have shown similar problems.)
So how do you fix a vending machine to keep people from stocking it with grenades? Human oversight of the stocking process might be the obvious answer, but it’s not one Facebook is likely to consider as more than a stopgap. There’s just too much money to be made through automation. The other possibility would be to make the vending machine smarter—to build in some new features that either more tightly restrict the size and shape of its contents or somehow automatically detect attempts to load it with contraband. Realistically, Facebook’s answer in the long run will be to make the vending machine smarter—that is, algorithmic.
Sophisticated algorithms come with their own pitfalls, of course, as Facebook knows from its experience with the news feed. But they’re likely to be a different set of problems than the one the company’s ad products are weathering now. When that time comes, critics will be justified in placing at least some blame on “algorithms.” Until then, the blame belongs squarely with the humans who didn’t bother to make Facebook’s wildly lucrative ad network smart enough to thwart the most obvious forms of abuse.