At Week 2 in Stanford’s machine learning course, the childishly simple homework assignments are growing more complex. Last week I wrote, “The great joy of learning new concepts in math and science is that they transport you into a simplified world, in which only a few things govern our lives and all problems can be solved—basically, a Richard Scarry book for the matriculating crowd.” In that case, we were making models of housing data based only on home size. Now we’ve got to worry about the number of floors and bathrooms, too. We’ve graduated from Richard Scarry to a more complex world that is beginning to get hairy.

Photograph by Ron Chapple/Jupiterimages/© Getty Images
So far, we’re still more occupied with student learning than machine instructing, though the path ahead is getting clearer. We’ve started learning a little programming in a language called Octave, which appears to be a graphing calculator on steroids, but it’s mostly to manipulate matrices, where we store data on all the values for the mathy part of this class. I understand that professor Ng has to introduce us into the really groundbreaking stuff gradually, once we have a strong command of the traditional ways that statistical modeling works, but right now I confess I feel more like I’m qualifying to be an actuary than a machine overlord.
This problem seems unavoidable; after all, Ng is teaching tens of thousands of people from different backgrounds. Online learning allows students to skip lectures that seem slow and review the PDFs of the notes instead. Personally, I prefer to watch and take notes, because understanding the professor’s teaching style makes understanding the material a lot easier. For now, I’m trying to stay patient with the slow progress. Neural networks and decision trees are just around the corner, according to the course schedule.
This week, we found out that you can make a model for like houses based on many data points—thousands if you like, down to the age and material in the roof, number of previous canine tenants, and so forth. We also learned that a straight line isn’t always the best sort of model to fit these data, which shouldn’t come as a surprise. Out here in the real world, reality rarely arranges itself according to straight lines.
This brings us to the “lazy hiker principle.” The real name for this technique is the “gradient descent algorithm,” but like I mentioned last week, the machine-learning professors could use a little help in marketing their material.
When you try to shoehorn real data into math world, you can try a huge number of possible models and before selecting the best one. Without getting into the all the formulas and Greek symbols, consider this lovely graph of undulating hills of blue and red. (The official rule in this series is now just one graph per post.)
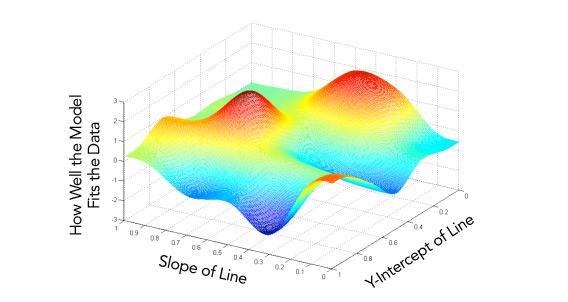
Chart by Andrew Ng/Stanford University.
All you need to know about this three-dimensional graph is that each point represents one possible model to fit our housing data. We want to find the bluest, lowest point, the one that does the best job of finding a model that predicts the going rate for houses not yet on the market.
To find this point, we place an imaginary hiker at different points with just one instruction: Walk only downhill until you can’t walk down anymore.
The reason we need our lazy hikers is that, unlike the cleanly visualized map above, we’re usually operating with far more complex models with hundreds or thousands of variables. We can see only three spacial dimensions, but our imaginary hikers can operate in as many dimensions as they like. Each step they take brings them closer to the absolutely perfect combination for our model.
But this doesn’t always work. Lazy hikers placed just a bit apart on the red hill will reach different points, one of which is a little higher from the ground than the other (and therefore a worse match for the data). The sort of problems we’re dealing with right now have only one valley, so it’s pretty easy for a single hiker to get where he needs to be and report back his coordinates. The hardest part here is choosing the right pace for each step, so that he doesn’t either overshoot his goal or take hours and hours and get where he’s going.
It turns out lazy hikers are more useful in very complicated problems, with lots of data points about each thing we’re trying to model and a huge number of examples of each. In these cases, the brute-force shortcut of using computers to multiply a bunch of matrices breaks down. The only solution is to make them smarter.Grades this week:
Linear Regression With Multiple Variables: 5/5, on fourth try. (Thanks to the reader who pointed out you can retake quizzes.)
Octave Tutorial, the programming language we’re going to be using: 3.4/5, minus 20 percent because I fell asleep and turned it in late.