
This article is part of Future Tense, a collaboration among Arizona State University, New America, and Slate. On Thursday, Dec. 10, Future Tense will host a three-hour conversation on “The Tyranny of Algorithms” in Washington, D.C. For more information and to RSVP, visit the New America website.
As violence continues in Jerusalem, it is worth remembering what people on both sides are fighting about is not just land or access or rights, but also symbolism.
This ancient city has many contested meanings attached to it. Israelis call it Yerushalayim in Hebrew, while Palestinians refer to it as Al Quds. Both sides also see it as the capital of their respective states.
Pretty much nobody else sees it as the capital of any state. The city does not host one single foreign embassy. But if you type “Jerusalem” into Google, you’re likely to see an infobox that declares the city as the “capital of Israel.” This happens when doing a search from the U.K., the U.S., from Israel, and from the Palestinian Territories (and presumably from many other parts of the world).
Google is known for its lack of transparency about how and why it chooses to display, promote, or omit certain kinds of information. But there are only two likely explanations for Google’s one-sided stance.
First, it is possible that this is conscious decision made by a Google manager or engineer seeking to make a political point. However, because of the sheer volume of searches that it mediates, the company tends not to manually override its more organic results.
The second, and far more likely, possibility is that (like almost all Google search results) answers are produced not through direct human meddling, but rather in a much more indirect form of curation through databases and the models and algorithms that govern them. Yet, in the case of Google decreeing that Jerusalem is the capital of Israel, it is likely happening because of an important change happening to the Web.
In the early days of the Web, content was stuck within its containers. Early Web pages built in HTML defined both their own content and their appearance. But things started to change after Tim Berners-Lee, the inventor of the Web, along with two colleagues, James Hendler and Ora Lassila, in 2001, outlined a vision for the creation of a Semantic Web. This would be a “Web of data” to replace the “Web of documents” that had been the result of the Web’s original design.
The subsequent adoption of a range of standards, formats, languages, and protocols such as XML, OWL, and RDF has made it more straightforward to disentangle form and content, allowing for much easier data exchange. Content could now be easily separated from its containers—and as a result, the Web could become machine-readable instead of just human-readable.
This has all begun to be put into practice through a few important platforms. The Wikimedia Foundation, for instance, has built a project called Wikidata that aims to turn a lot of the information from Wikipedia into linked, structured, data. When new statistics for the population of Nairobi, or any other city, are released, these can be edited into Wikidata and then propagated to many of the hundreds of versions of Wikipedia, instead of humans slowly, manually, editing each of those versions.
Google is trying to go a step further by building what they call a Knowledge Graph: a knowledge base that can gather information from Wikidata, Wikipedia, Freebase (another user-generated knowledge base), and a range of other sources. On releasing it in 2012, Google described the system as “a critical first step towards building the next generation of search, which taps into the collective intelligence of the web and understands the world a bit more like people do.”
In practice, what this means is that the search engine can attempt to understand intent (Georgia the country, or Georgia the state?), and summarize content in infoboxes—like displaying the area or population of a city. As a result, users rapidly get answers to straightforward questions and never have to navigate away to another site.
Previously, Google offered a ranked list of links without attempting to wade into messy debates about truths. Now the Knowledge Graph (and the infoboxes that its content is placed within) displays information as factual. And this is where problems begin to arise.
My colleague Heather Ford, a research fellow at the University of Leeds, and I set out to study what a move toward a more Semantic Web (that is, what a move toward a more machine-readable Web) might mean for urban politics. We’ve concluded that there are three key issues.
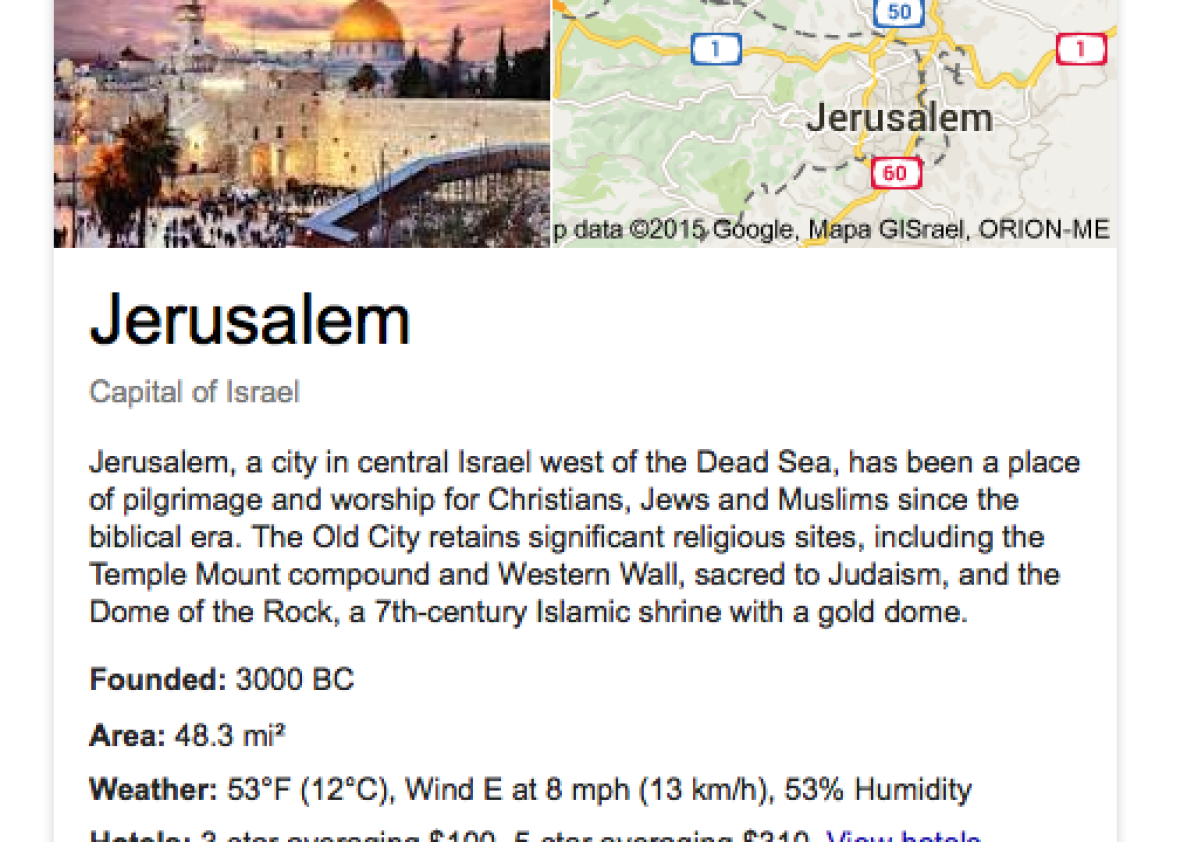
Screenshot via Google
First, because of the ease of separating content from containers, the provenance of data is often obscured. Contexts are stripped away, and sources vanish into Google’s black box. For instance, most of the information in Google’s infoboxes on cities doesn’t tell us where the data is sourced from.
Second, because of the stripping away of context, it can be challenging to represent important nuance. In the case of Jerusalem, the issue is less that particular viewpoints about the city’s status as a capital are true or false, but rather that there can be multiple truths, all of which are hard to fold into a single database entry.
Finally, it’s difficult for users to challenge or contest representations that they deem to be unfair. Wikidata is, and Freebase used to be, built on user-generated content, but those users tend to be a highly specialized group—it’s not easy for lay users to participate in those platforms. And those platforms often aren’t the place in which their data is ultimately displayed, making it hard for some users to find them. Furthermore, because Google’s Knowledge Base is so opaque about where it pulls its information from, it is often unclear if those sites are even the origins of data in the first place.
Jerusalem is just one example among many in which knowledge bases are increasingly distancing (and in some case cutting off) debate about contested knowledges of places. Google searches conducted in London show a range of places in which Google’s databases pick sides in contested political situations. A search for “Londonderry”(the name used by unionists) in Northern Ireland is corrected to “Derry” (the name used by Irish nationalists). A search for Abu Musa lists it as an Iranian island in the Persian Gulf. This stands in stark contrast to an Arab view that the island belongs to the United Arab Emirates and that it is instead in the Arabian Gulf. In response to a search for Taipei, Google claims that the city is the capital of Taiwan (a country only officially recognized by 21 U.N. member states). Similarly, the search engine lists Northern Cyprus as a state, despite only one other country recognizing it as such. But it lists Kosovo as a territory, even though it’s formally recognized by 112 other countries.
My point is not that any of these positions are right or wrong. It is instead that the move to linked data and the semantic Web means that many decisions about how places are represented are increasingly being made by people and processes far from, and invisible to, people living under the digital shadows of those very representations. Contestations are centralized and turned into single data points that make it difficult for local citizens to have a significant voice in the co-construction of their own cities.
None of this is to say that a more semantic Web doesn’t offer an incredible amount of utility. Linked data organized through the semantic Web can be easily integrated, repurposed, collected, classified, published, and indexed. It is, however, important to recognize that making the Web more machine-readable comes with a price.
Linked data and the machine-readable Web have important implications for representation, voice, and ultimately power in cities, and we need to ensure that we aren’t seduced into codifying, categorizing, and structuring in cases when ambiguity, not certainty, reigns. There is perhaps still much to be said for a Web more tailored to humans rather than machines.