
Last month, I wrote about the fun and the pitfalls of viral maps, a feature that included 88 super-simple maps of my own creation. As a follow-up, I’m writing up short items on some of those maps, walking through how I created them and how they succumb (and hopefully overcome) the shortfalls of viral cartography.
Here is one map that used Wikipedia as a data set.
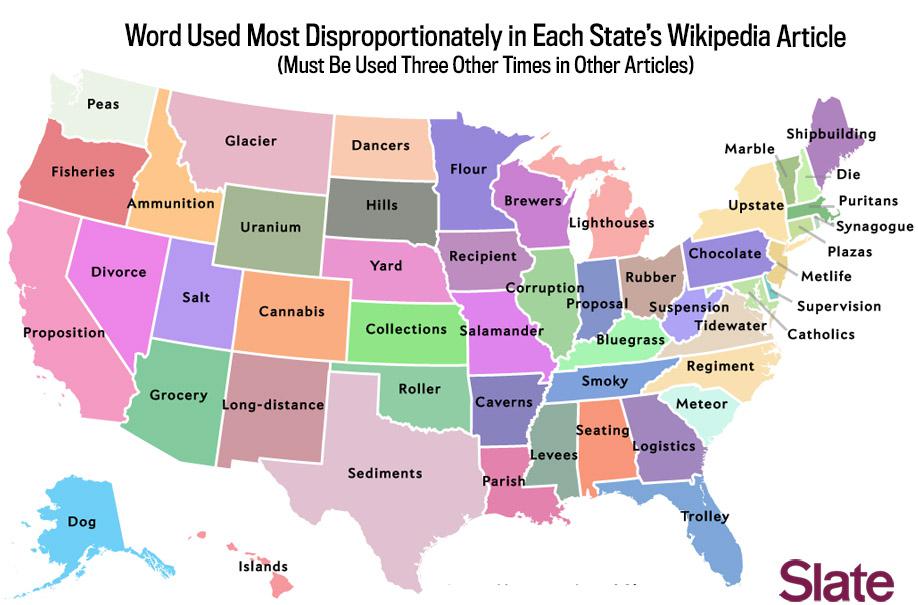
Data source: Wikipedia articles accessed March 2014. Map by Ben Blatt/Slate.
The user-written encyclopedia, unknowingly, confirms many of our suspicions about each state. Colorado’s Wikipedia page is littered with talk of cannabis, Nevada’s article talks about divorce, and Pennsylvania (the home of Hershey’s) is labeled chocolate.
I calculated which word was used most disproportionately by looking at each word’s frequency within the state’s page compared with its frequency in the pages for all 50 states. This means that words that show up in a whole bunch of articles would be unlikely to make any state’s list. I also needed to use a cutoff to exclude words that appeared very rarely—if a word showed up once on the Texas page and zero times elsewhere, it would be hard to call its use disproportionate. In the map above, I used an arbitrary cutoff, limiting the selection to words used at least three times in other articles.
Here’s a dirty secret of viral maps: Change that arbitrary cutoff, and you’ll get something that looks completely different. Here’s the map with a cutoff of 10.
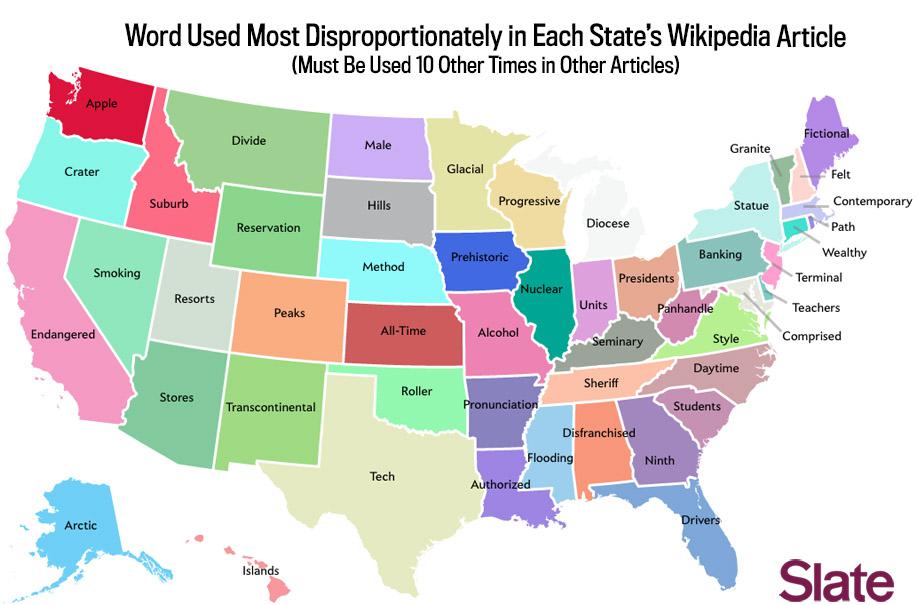
Data source: Wikipedia articles accessed March 2014. Map by Ben Blatt/Slate.
North Dakota is suddenly described as males instead of dancers, and New Hampshire goes from decreeing “Live Free or Die” to “Live Free or Felt.”
Why use the disproportionate method at all? Why not just look at the most common words in each article? Well, if we do that, the results are a bit less interesting.
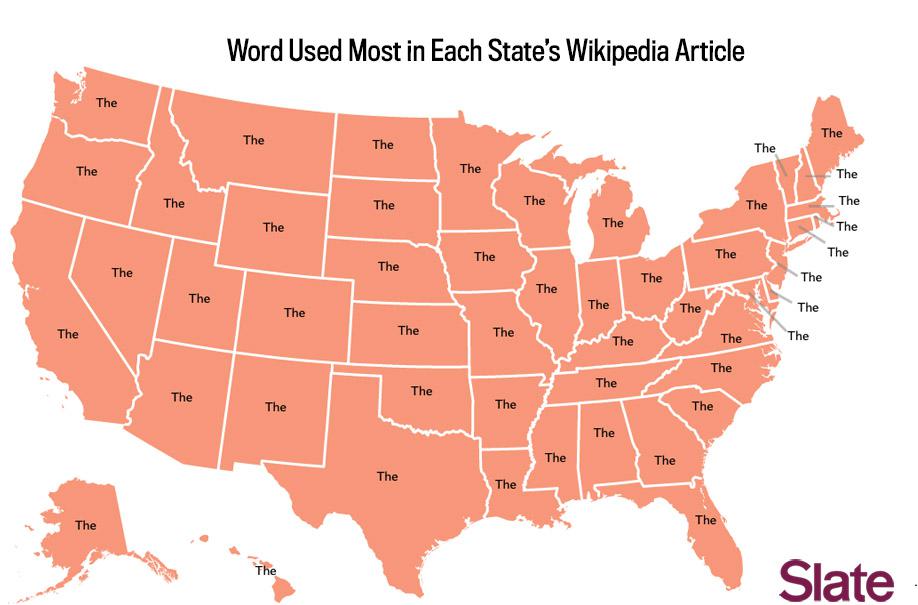
Data source: Wikipedia articles accessed March 2014. Map by Ben Blatt/Slate.
See more of Slate’s maps.